This post is a continuation of sorts of my post the other day about using t-tests with experiments. I have been reading and researching all day, but I haven’t seen anybody really addressing the fact that there seem to be two different kinds of models for experiments that we treat the same, at least in AP Stats, but really aren’t. Two examples are given.
Experiment 1 – the “treatment causes a change” model
50 students are given caffeine pills and 50 students are given a placebo sugar pill. Both groups take a 100-point test. The placebo group scores an average of 75 with a SD of 9. The caffeine group scores an average of 79 with a SD of 11. Is this evidence that the caffeine led to a change in test scores for these students, on average?
Experiment 2 – the “which treatment is better” model
100 allergy-sufferers record the number of times they sneeze in a 24 hour period. Then 50 of them are given Claritin and 50 of them are given Zyrtec and asked to record the next 24 hours. The average user of Claritin had their sneeze level decrease by 28% with a standard deviation of 9%. The average user of Zyrtec had their sneeze level decrease by 33% with a standard deviation of 14%. Is there evidence that the treatments affect sneeze level differently for these participants on average?
Where I’m bugged
In AP Statistics, as far as I know, both of these experiments would be tackled the same way – with a 2-sample T-test. In both cases we would write our null hypothesis as “
My problem is that these experiments really imply fundamentally different models for me. In the first problem, the “control” response and the “treatment” response are fundamentally linked on an individual-by-individual basis. That is, a volunteer in the control group who gets a 98 on the test would almost certainly get a high grade in the treatment group as well. In this case, what we really mean our null hypothesis to be is “each individual would score the same whether they received the placebo or the caffeine.” This is a perfect opportunity for a permutation test. Permutation tests are awesome. They fit this model perfectly, they are easy to understand. And in many cases where assumptions are met (not too crazy-skewed treatment data, decent sample sizes) a t-test p-value seems to match a permutation test almost perfectly. This connects back to my idea of the ‘randomization distribution’ in my last post, I’m pretty sure; in this case, the randomization distribution looks a lot like the sampling distribution made from a sampling situation with the same numbers.
The second problem, though, is a really different model in my mind. In this case, we have no reason to believe that a specific individual’s responses to the two variables are particularly linked. Claritin and Zyrtec are different medications and people respond differently to them. My wife responds better to Zyrtec than Claritin, while I am the opposite. This is expected. In this case, the null hypothesis we MEAN isn’t actually “a specific individual will respond to the same treatments” – it’s instead much closer to what we actually wrote, “the average response to Claritin would have been the same as the average response to Zyrtec among these participants if they had all received both medications, even though specific individuals might vary significantly.” A permutation test, in this case, doesn’t make sense; if I permute an individual to the other treatment I have no reason, under this null, to assume that specific individual would have the same result even if the null is true.
These match the same ideas I talked about a little in my last post, but even leaving out the idea of randomization distributions I brought up there, the fact is that the actual t-test procedures we would use in AP stats works really differently under these models, based on my simulations.
Simulating the first experiment
I randomly chose 100 numbers from N(75, 9) to represent the scores my participants would have received under the control. For each of those, I then picked a number from N(4, 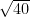
Results? With this population, a 95% confidence interval using T-distributions captured the true difference about 96% of the time. The power of the t-test was about 60%, which isn’t bad and in line with what I would expect.
I then modified the code to create a population that DOESN’T really have a difference, but kept some variation in the SD. Basically set the average increase value to 0 instead of 4, leaving everything else the same. R code here. In this one, the 95% CI hit rate was still about 96%, and the % of trials that find a difference (when there ISN’T one, or at least not a big one) is about 4.5% – very close to alpha, which SHOULD be the value here since these are type I errors. These numbers all seem to imply that a t-test the way we do it in AP stats makes a lot of sense for this situation, and works pretty well.
Simulating the second experiment
For this one, I generated 100 values from N(28,9) and 100 values from N(33,14) to represent the responses my individuals would have had under Claritin or Zyrtec. Everything else was the same. R code here.
Results? The 95% confidence interval has a hit rate of 99.2% – WAY higher than intended. The power of the test in this context is around 56%, which is hard to interpret – is that what it should be?
I then ran the no-difference modification, setting the Zyrtec values to be from N(28,14) instead of N(28,9). In this case, the average difference is actually 0, so the null is met. In this situation, I still got about a 99% confidence interval hit rate even though I was aiming for 95%, and only 0.6% of the randomizations resulted in rejecting the null. This seems like a good thing at first glance, but my alpha was 0.05, so I should have had about a 5% error rate, not a 0.6% error rate! In other words, the T-distribution we would use in AP stats does NOT seem to work as advertised in this case.
The correction factor
It turns out there is a correction factor I can use on the independence case that solves this problem: it brings confidence interval hit rates to 95%, increases the power of the test when there is a difference, and brings P(Type I error) to about 5% when there isn’t one. All I had to do is reduce the standard error used in the t-calculations by a factor of 
Conclusion
Some experiments – the ones where a permutation test makes sense – seem to be pretty well matched by t-tests when the data in the experiment are normalish. But experiments where individuals are expected to vary and we are just concerned with the average response difference, not so much. In that situation, a matched-pairs scenario would be required, I think, to get anything good out of the data, though my simulations imply that using a correction factor with a standard 2-sample test could result in reasonable values.
Edited Conclusion
Oh my goodness. So, it turns out you can still make the second kind of experiment match a t-distribution quite nicely. How? Change the stem and the conclusion just a bit. Instead of “Is there evidence that the treatments affect sneeze level differently for these participants on average?” instead say “Is there evidence that the treatments would affect the sneeze level of people like these differently, on average?” This stem implies both random assignment AND random sampling from some nebulous population that looks like the participants. In other words, we add extra variability. I did a sim (no R code provided because it would crash r-fiddle pretty thoroughly, feel free to e-mail me for it though) that confirms this: I drew 1000 different groups of volunteers from a normal population then repeated the process from above for each group (a total of 1 million randomizations!) Combining all differences together and comparing each to the population difference resulted in pretty much perfect interval and test results.
However, if you do that same thing with the FIRST kind of experiment (the kind that already worked pretty well) then it BREAKS the t-distribution! So the first kind of experiment, that can be modeled by a permutation test, can be approximated with a t-distribution as long as you only draw a conclusion WITHIN THE GROUP with no inference to larger populations at all, even ones “like these.” The second kind works with a t-distribution only if you DO draw a conclusion from a population of “people like these.” (and this is with nice normal distributions all around – I’m sure skewed would break these in other ways). AAAAAHHHH!